
[카테고리:] 예술
-
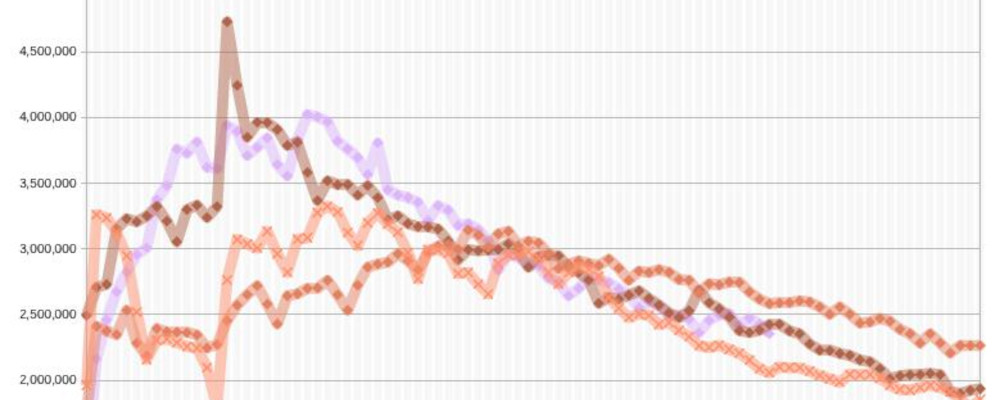
2024년 상반기 여자 아이돌 스포티파이 정리 / 뉴진스 비교
올해 아이돌 관련해서 가장 이슈가 있던 사건은 하이브-민희진 간의 갈등이다. 개인적으로 해외에서 뭔가 볼법한 일이 국내에서 일어나서 흥미로웠다. 민희진의 인터뷰에서 가장 흥미로웠던 것은 자신에 대한 확신이었고, 스포티파이의 스트리밍 실적을 보면 확실히 뉴진스가 블랙핑크, 피프티피프티를 제외하고 가장 뛰어났다. (참고로 피프티피프티는 Cupid 만 성공을 했지만, 이곡의 세가지 버전을 합치면, 블랙핑크의 How You Like That 보다 스트리밍이 더…
작성자
-
한국 전통 회화 모델 제작기 (SDXL 기반)
Traditional Korean Painting Model production history (based on SDXL) (Translated from English using DeepL) 하이퍼네트워크와 SD1.5 기반의 모델을 만들고 난 뒤 몇 달 지나지 않아 SDXL이란 모델이 나왔습니다. 그 당시 SD2.1 기반의 모델은 작업을 하지 않았습니다. 그 이유는 컨트롤넷을 사용하기 어려운 점과 명확하게 SD1.5 보다는 낫지 않았기 때문에 꺼려졌습니다. 프롬프트에 따른 변화는 명확하게 줄 수…
작성자

-
한국 수묵화 모델 사용 가이드 (SD1.5기반)
이전에 제작했던 하이퍼넷트워크에 이어서 이번엔 파인튜닝 한 나온 모델을 공유합니다. 그리고 모델 사용 가이드로 남깁니다. 데이터는 공유마당에 있는 김홍도 그림 중 선별 한 자료와 Ai허브에 올라와 있는 한국화 데이터셋 입니다. 모델에 사용된 자료 출처 공유마당 링크 / Ai허브 링크 허깅페이스 모델 주소 https://huggingface.co/gagong/korean-sumukhwa-model-ver-1 Civitai 주소 https://civitai.com/models/81845/ 학습과정 이미지를 768×768사이즈로 바꾼뒤, clip_interrogator를 통해 프롬프트를 만들었습니다. 이후…
작성자

-
만약 김홍도가 해외여행을 한다면?
단원 김홍도가 유럽을 여행하면 어떤 그림을 그릴지 궁금하다면? 김홍도 그림으로 파인튜닝 한 모델을 가지고 유럽의 사진을 변환했습니다. 일단 유럽의 대표적인 도시의 풍경부터 변환을 해봤습니다. 계획상에는 유럽의 자연경관도 당연히 있습니다. 알프스나 유럽의 포도밭 그리고 이탈리아의 해안도 담을 예정입니다. 건축물보다 자연경관에서 어떠한 결과물이 나올지 궁금해지는데, 풍속화가 유명하긴 하지만 들어간 데이터는 자연을 그린 그림들이 많기 때문입니다. 참고로 인스타…
작성자

-
짭홍도 HyperNetworks를 만든 것에 관하여, ai 그림 제작
6월 5일 추가 / 최근에 미세조정(파인튜닝)한 모델을 공개했습니다. 그것에 대해선 이 글을 참고해 주세요. ai 그림으로 유명한 스테이블 디퓨전에서 have i been trained? 이란 사이트를 만들었습니다. (학습에 사용된 이미지 검색하는 사이트) 김홍도나 한국화에 관한 단어를 검색하게 되었고, 빈약한 것을 발견하고 외쳤습니다. 그렇다! 여기가 빈땅이구나. 블루오션이다! 그리고 자료를 모으고 가공한다는 점에서 블로그 컨셉과도 잘 맞는다고 약간의…
작성자
